Voice Activity Detection
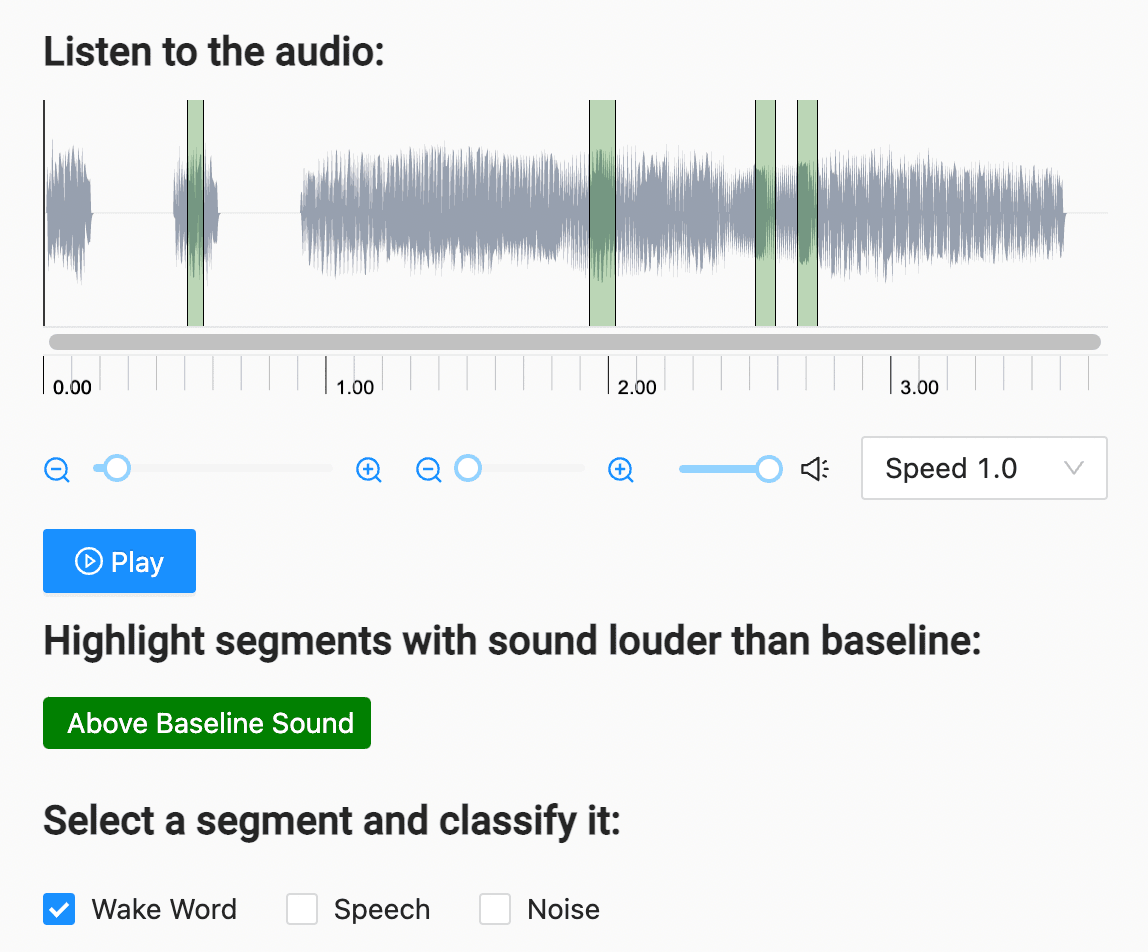
If you want to train a voice activity detection (VAD) model for automating call center interactions, improving voice-activated assistant systems, or other speech detection use cases, you can use this template. Create segments of the audio clip that possibly include speech, then classify each segment as to whether it includes speech, a specific wake word for voice-activated assistant system use cases, or is simply noise.
Interactive Template Preview
Labeling Configuration
<View>
<Header value="Listen to the audio:"></Header>
<Audio name="audio" value="$url" zoom="true"></Audio>
<Header value="Highlight segments with sound louder than baseline:"></Header>
<Labels name="label" toName="audio" choice="multiple">
<Label value="Above Baseline Sound" background="green" alias="possible-speech"></Label>
</Labels>
<Header value="Select a segment and classify it:"></Header>
<Choices name="voice" toName="audio" choice="multiple" showInline="true" perRegion="true">
<Choice value="Wake Word" alias="wake-word"></Choice>
<Choice value="Speech" alias="plain-speech"></Choice>
<Choice value="Noise" alias="not-speech"></Choice>
</Choices>
</View>About the labeling configuration
All labeling configurations must be wrapped in View tags.
You can add a header to provide instructions to the annotator:
<Header value="Listen to the audio:"></Header>Use the Audio object tag to specify the location of the audio file to process:
<Audio name="audio" value="$url"></Audio>Use the Labels control tag to allow annotators to segment the audio and identify possible spots where speech might be present.
<Labels name="label" toName="audio" choice="multiple">
<Label value="Above Baseline Sound" background="green" alias="possible-speech"></Label>
</Labels>The choice="multiple" parameter allows one audio segment to be labeled with overlapping labels. The alias parameter lets you specify a name for the label in the exported annotations that is different from what appears to annotators.
Use the Choices control tag to prompt annotators to classify the type of sound in each audio segment:
<Choices name="voice" toName="audio" choice="multiple" showInline="true" perRegion="true">
<Choice value="Wake Word" alias="wake-word"></Choice>
<Choice value="Speech" alias="plain-speech"></Choice>
<Choice value="Noise" alias="not-speech"></Choice>
</Choices>The choice="multiple" parameter allows annotators to select both “Speech” and “Wake Word” as options for a specific segment. The perRegion parameter means that each classification applies to a specific audio segment.